
Recently at work, i came with a project called Seeds – Its a curated/prepared dataset which we send through our pipeline and at the end of it, we verify the expected vs actual results.

Expected You say ? – since the dataset is custom prepared by us, we are aware of its nature and hence know what to expect. Example: Prepare a dataset of 100 orders for customer ‘Adam’ and push it thru your pipeline. I expect select count(*) from orders where customer =’Adam’ ==== 100 at the end of the pipeline.

So i came up with Harvestor, its a github workflow which does the pipeline setup, plants the seeds (send the data) and does various verification steps at various checkpoints in the pipeline. At the end, it verifies the Harvest, i.e the final result.The normal github pipelines looked 🥱☹️, So i sprinkled a little Emojis to brighten up the place 🤗
The project naming also resonated well with my team mates too!
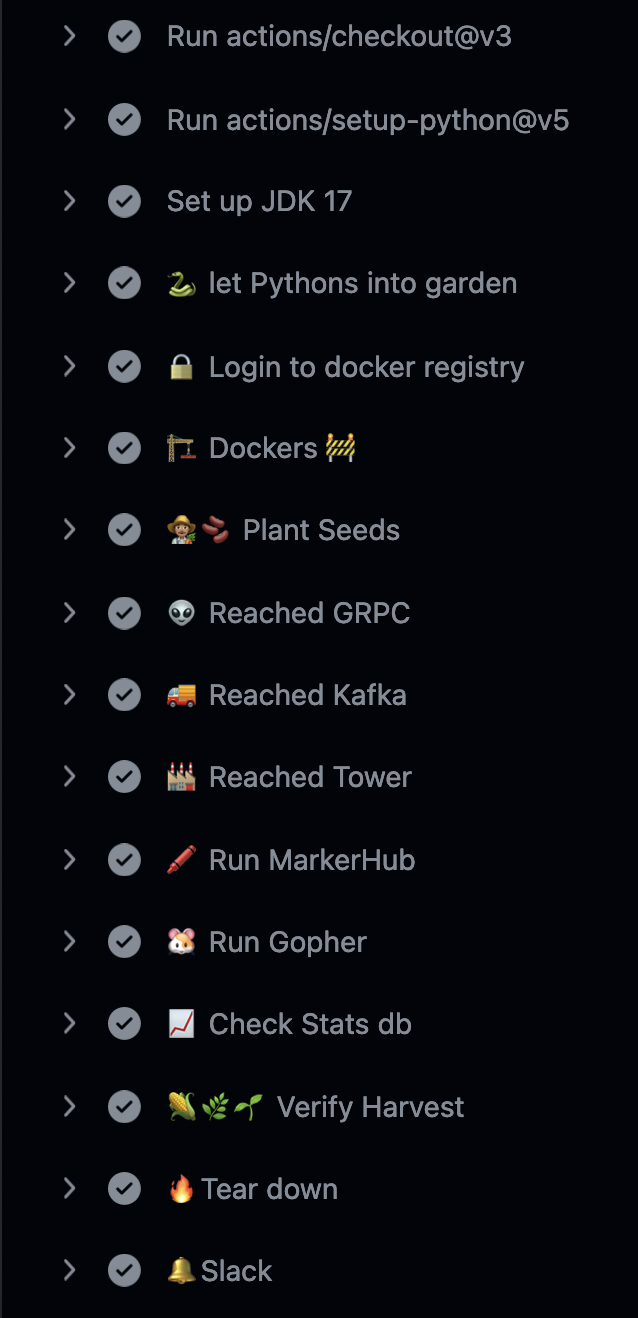
That combined with nice icons for slack channel – made the cake complete with cherries.
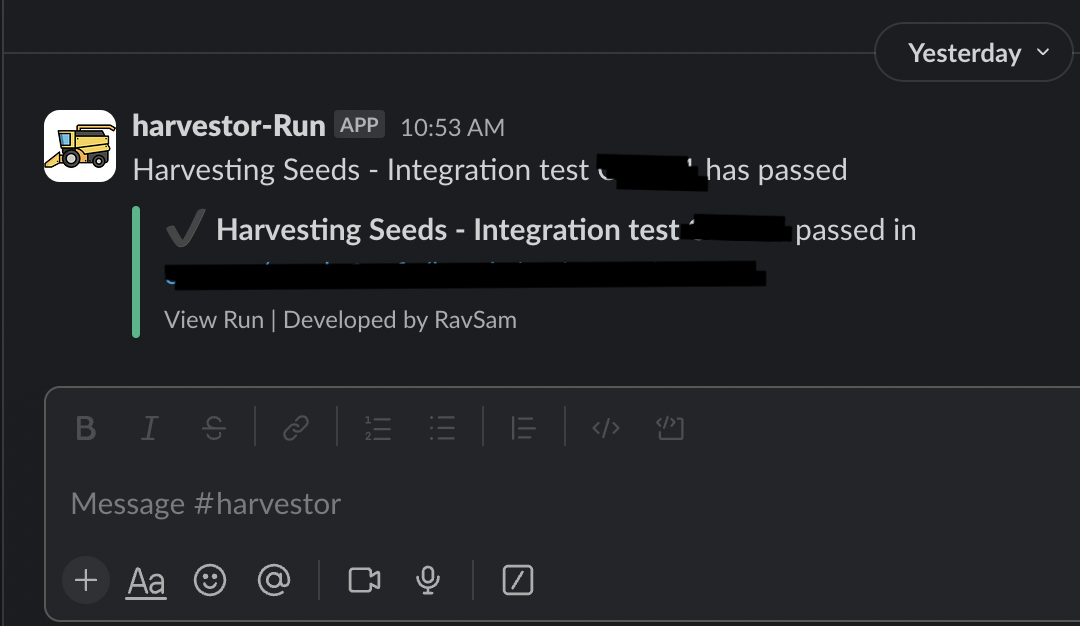
I call this DATA Art or DartA.
let me know what you think. Hope this inspires you.



